 While much of the knowledge needed to develop software is captured in some form of documentation, there is often a gap between the information needs of software developers and the structure of this documentation. Any kind of hierarchical structure with sections and subsections can only enable effective navigation if the section headers are adequate cues for the information needs of developers.
While much of the knowledge needed to develop software is captured in some form of documentation, there is often a gap between the information needs of software developers and the structure of this documentation. Any kind of hierarchical structure with sections and subsections can only enable effective navigation if the section headers are adequate cues for the information needs of developers.
To help developers navigate documentation, during my PostDoc with Martin Robillard at McGill University, we developed a technique for automatically extracting task descriptions from software documentation. Our tool, called TaskNav, suggests these task descriptions in an auto-complete search interface for software documentation along with concepts, code elements, and section headers.
We use natural language processing (NLP) techniques to detect every passage in a documentation corpus that describes how to accomplish some task. The core of the task extraction process is the use of grammatical dependencies identified by the Stanford NLP parser to detect every instance of a programming action described in a documentation corpus. Different dependencies are used to account for different grammatical structures (e.g., “returning an iterator”, “return iterator”, “iterator returned”, and “iterator is returned”):

In the easiest case, a task is indicated by a direct object relationship, as in the example shown above. TaskNav uses this information to extract two tasks descriptions from the example sentence: “generate receipt” and “generate other information”.

When passive voice is used, the passive nominal subject dependency connects the action and the object. In this case, TaskNav finds the task “set thumbnail size in templates”.
 Some actions do not have a direct object. In those cases, TaskNav follows the preposition dependency and would extract the task “integrate with Google Checkout” from the example sentence above.
Some actions do not have a direct object. In those cases, TaskNav follows the preposition dependency and would extract the task “integrate with Google Checkout” from the example sentence above.
Once the TaskNav user runs a search query after selecting the search terms from auto-complete, search results are presented in a sidebar. When the user selects a result, the corresponding document is opened in TaskNav. The paragraph that matched the query is highlighted, and the document is automatically scrolled to that paragraph.
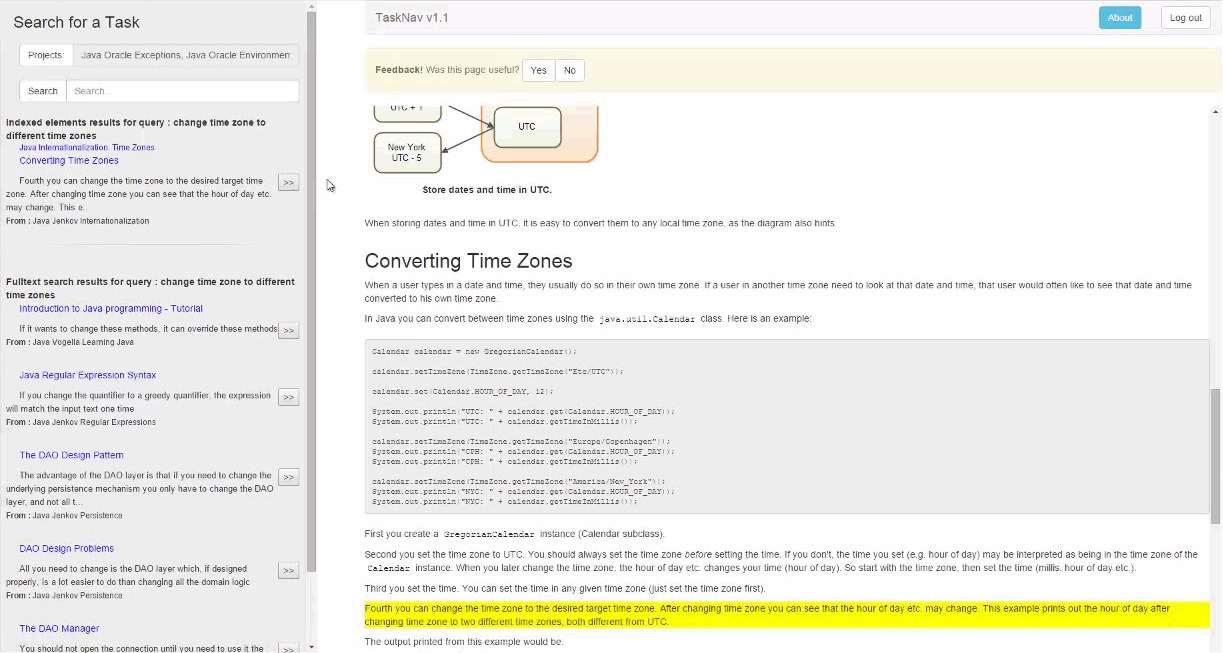
We conducted a field study in which six professional developers used TaskNav for two weeks as part of their ongoing work. We found search results identified through extracted tasks to be more helpful to developers than those found through concepts, code elements, and section headers.
TaskNav can automatically analyze and index any documentation corpus based on a starting URL and some configuration parameters, such as which HTML tags should be ignored. Documentation users can benefit from TaskNav by taking advantage of the task-based navigation offered by the auto-complete search interface. For documentation writers, TaskNav provides analytics that show how documentation is used (e.g., top queries, most frequently read documents, and unsuccessful searches). Researchers can benefit from the data accumulated by TaskNav’s logging mechanism as it provides detailed data on how software developers search and use software documentation.
All the details of our work on TaskNav are now available as a journal paper in IEEE Transactions on Software Engineering [link] [preprint], and TaskNav will also appear as a Demo at ICSE 2015.
