 This blog post is based on our MSR 2017 paper.
This blog post is based on our MSR 2017 paper.
Software developers author a wide variety of documents in natural language, ranging from commit messages and source code comments to documentation and questions or answers on Stack Overflow. To uncover interesting and actionable information from these natural language documents, many researchers rely on “out-of-the-box” natural language processing (NLP) libraries, often without justifying their choice of a particular library. In a systematic literature review, we identified 33 papers that mentioned the use of an NLP library (55% of which used Stanford’s CoreNLP), but only 2 papers offered a rudimentary justification for choosing a particular library.
Software artifacts written in natural language are different from other natural language documents: Their language is technical and often contains references to code elements that a natural language parser trained on a publication such as the Wall Street Journal will be unfamiliar with. In addition, natural language text written by software developers may not obey all grammatical rules, e.g., API documentation might feature sentences that are grammatically incomplete (e.g., “Returns the next page”) and posts on Stack Overflow might not have been authored by a native speaker.
To investigate the impact of choosing a particular NLP library and to help researchers and industry choose the appropriate library for their work, we conducted a series of experiments in which we applied four NLP libraries (Stanford’s CoreNLP, Google’s SyntaxNet, NLTK, and spaCy) to 400 paragraphs from Stack Overflow, 547 paragraphs from GitHub ReadMe files, and 1,410 paragraphs from the Java API documentation.
Comparing the output of different NLP libraries is not trivial since different overlapping parts of the analysis need to be considered. Let us use the sentence “Returns the C++ variable” as an example to illustrate these challenges. The results of different NLP libraries differ in a number of ways:
- Tokenization: Even steps that could be considered as relatively straightforward, such as splitting a sentence into its tokens, become challenging when software artifacts are used as input. For example, Stanford’s CoreNLP tokenizes “C++” as “C”, “+”, and “+” while the other libraries treat “C++” as a single token.
- General part-of-speech tagging (affecting the first two letters of a part-of-speech tag): Stanford’s CoreNLP mis-classifies “Returns” as a noun, while the other libraries correctly classify it as a verb. This difference can be explained by the fact that the example sentence is actually grammatically incomplete—it is missing a noun phrase such as “This method” in the beginning.
- Specific part-of-speech tagging (affecting all letters of a part-of-speech tag): While several libraries correctly classify “Returns” as a verb, there are slight differences: Google’s SyntaxNet classifies the word as a verb in 3rd person, singular and present tense (VBZ) while spaCy simply tags it as a general verb (VB).
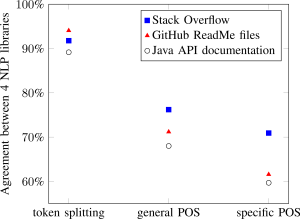
The figure at the beginning of this blog post shows the agreement between the four NLP libraries for the different documentation sources. The libraries agreed on 89 to 94% of the tokens, depending on the documentation source. The general part-of-speech tag was identical for 68 to 76% of the tokens, and the specific part-of-speech tag was identical for 60 to 71% of the tokens. In other words, the libraries disagreed on about one of every three part-of-speech tags—strongly suggesting that the choice of NLP library has a large impact on any result.
To investigate which of the libraries achieves the best result, we manually annotated a sample of sentences from each source (a total of 1,116 tokens) with the correct token splitting and part-of-speech tags, and compared the results of each library with this gold standard. We found that spaCy had the best performance on software artifacts from Stack Overflow and the Java API documentation while Google’s SyntaxNet worked best on text from GitHub. The best performance was reached by spaCy on text from Stack Overflow (90% of the part-of-speech tags correct) while the worst performance came from SyntaxNet when we applied it to natural language text from the Java API Documentation (75% of the part-of-speech tags correct). Detailed results and examples of disagreements between the gold standard and the four NLP libraries are available in our MSR 2017 paper.
This work raises two main issues. The first one is that many researchers apply NLP libraries to software artifacts written in natural language, but without justifying the choice of the particular NLP library they use. In our work, we were able to show that the output of different libraries is not identical, and that the choice of an NLP library matters when they are applied to software engineering artifacts written in natural language. In addition, in most cases, the commonly used Stanford CoreNLP library was outperformed by other libraries, and spaCy—which provided the best overall experience—was not mentioned in any recent software engineering paper that we included in our literature review.
The second issue is that the choice of the best NLP library depends on the task and the source: For all three sources, NLTK achieved the highest agreement with our manual annotation in terms of tokenization. On the other hand, if the goal is accurate part-of-speech tagging, NLTK actually yielded the worst results among the four libraries for Stack Overflow and GitHub data. In other words, the best choice of an NLP library depends on which part of the NLP pipeline is going to be employed. In addition, while spaCy outperformed its competition on Stack Overflow and Java API documentation data, Google’s SyntaxNet showed better performance for GitHub ReadMe files.
The worst results were generally observed when analyzing Java API documentation, which confirms our initial assumption that the presence of code elements makes it particularly challenging for NLP libraries to analyze software artifacts written in natural language. In comparison, the NLP libraries were less impacted by the often informal language used in GitHub ReadMe files and on Stack Overflow. Going forward, the main challenge for researchers interested in improving the performance of NLP libraries on software artifacts will be the effective treatment of code elements. We expect that the best possible results will eventually be achieved by models trained specifically on natural language artifacts produced by software developers.
